
C programlama dilinin ANSI standartlarına göre resmi kabulü uzun bir süre önce başladı. biz bu konulara değinmeyeceğiz.
Burada öğreneceğimiz C, standart C değildir ancak çok küçük farklılıkları vardır. Biz buna Arduino C diyelim…
Yapı Blokları
Tüm progrmlama dilleri 4 temel öğeden oluşmuştur;
1- Deyimler
2- İfadeler
3- İfade Blokları
4- Fonksiyon Blokları
Son öğe olan fonksiyon blokları değişik dillerde farklı farklı isimlendirilmişlerdir ancak genel olarak yaptıkları iş hepsinde aynıdır: belirlenen işi yapacak olan ifadeleri göstermesi için dizayn edilmiş kod bloğudurlar.
Deyimler
Deyim(expression), operand ve operatörlerin bir araya gelmesinden oluşur.
Basitçe söylemek gerekirse bir operand, operatör tarafından üzerinde işlem yapılacak veri parçasıdır.
Operatör ise operand üzerinde matematiksel veya lojik işlemler gerçekleştirecek olan aksiyonlardır.
a + b
m-300
k>9
İfadeler
c=49;
a=b+c;
AlininYasi=VelininYasi/2;
Peki, değişken nedir? basitçe söylemek gerekirse, memory de adresli bir bölgedir ve buraya bir isim atanmıştır. İlk örnekte c ismi atanmış bir bölgenin içine 49 değeri kaydedilmiştir. İleriki konularda değişkenlere daha fazla değinilecektir.
İkinci ifadede, sonunda ; işareti olan karmaşık bir deyim görmekteyiz. Bu örnekte, a değişkenine atanacak olan değer henüz bilinmemekte o yüzden bu değeri bulabilmek için öncelikle b+c deyiminin çözümlenmesi gerekiyor.
Eğer b=4 ve c=5 olduğunu düşünürsek, karmaşık deyimi aşağıdaki gibi çözümleyebiliriz;
a=9
çözümlemedeki son deyim, 9 değerini a değişkeninin içerisine atar. Satırın sonuna ; işaretini koymakla birlikte deyim, a değişkeninin içeriğini 9 ile değiştiren ifade şekline gelir.
Burada şunu belirtmeliyiz; C compilerın görevi, ingilizce benzeri deyimleri (syntax= yazdığımız 1 satır komut olarak da düşünülebilir) mikroişlemcinin anlayabileceği 1 ve 0 lara dönüştürmektir. İşte her deyimin sonuna koyduğumuz ; işareti deyimi ifadeye çevir ve compiler a şunu söyler ” compiler kardeş, bu ifadede belirttiğim işleri yap bakalım sonucu ne olacak. “. Eğer yazdığımız ifadede bir sorun yoksa, compiler bu ifadeyi makine diline çevirir (1 ve o lardan oluşan bir sürü değer), eğer herhangi bir hata mesajı vermediyse syntax olarak bir hatamız yok demektir. Ancak hata vermemesi demek o kodun her zaman doğru çalışacağı anlamına gelmez, yazdığımız ifadede tamamen alakasız ve saçma sapan bir şeyler de istemiş olabiliriz. O yüzden ne yazdığımıza dikkat etmeli, ne istediğimizi iyi bilmeliyiz.
Eğer aşağıdaki gibi daha karmaşık ifademiz olursa ne olur?
x= a + b – c + g + h + k;
compiler x’e yeni değerini atamadan önce tüm ara değerleri (örnektekiler=a+b, c+g, h+k) çözümler. Compiler’a ifadeyi çözümleyecek ihtiyaç olunan tüm ara değerlerin mevcut olduğunu söyleyen, ifadenin sonundaki , işaretidir. Compiler ; işaretini görünce ifadedeki operatör önceliklerine göre ara değerleri belirler ve işlemi yapar.
Operatör Öncelikleri
Varsayalım aşağıdaki gibi birkaç deyimi kapsayan bir ifademiz var:
j = 5 + k * 2 ;
diyelim k=3 ve * işareti çarpma operatörü. j=16 mı olur (8×2=16), yada j=11 mi olur (5+6=11) sizce hangisi?
Eğer hangi karmaşık deyimin önce çözümleneceğinden tam olarak emin olamazsak ifade bize birden çok anlam ifade edebilir.
j=16; j=11;
Sonuç, karmaşık ifadeyi hangi sıraya göre çözümlediğimize göre değişir. C bu gibi belirsizlikleri, her operatöre ( + , – , * , / v.b) atadığı öncelik seviyelerine göre çözümler. Operatör öncelikleri, kompleks ifadelerin çözümlenme sıralamasını belirler. Aşağıdaki listede operatör önceliklerinin küçük bir kısmını görebilirsiniz.
2 +, –
Listede görüleceği gibi, çarpma, bölme ve mod alma((%)modulo-bölmeden arda kalan) operatörleri toplama ve çıkarma operatörlerinden önce işleme tabi tutulur. Bu yüzden yukarıdaki sorunun cevabı j=11 dir çünkü çarpma işlemi önce yapılmaktadır.
İfade Blokları
İfade blokları bir veya daha fazla gruplanmış ifade içerir, compiler tarafından tek bir ifadeymiş gibi görüler. Örneğin, varsayalım siz bir apartmanda yöneticisiniz ve dışarıda yerler 4 cm karla kaplanmış, siz de yerdeki karları kürüyeceksiniz.
İfade aşağıdaki gibi olurdu; (>= operatörü “büyük veya eşit” olarak okunur)
if (kar >= 4) {
KardaCalismaKiyafetleriniGiy();
KarKureginiAl();
YerdekiKarlarıKure();
} else {
YatagaGeriDon();
}
İfade blokları Süslü parantez ‘ {‘ ile başlar ve tekrar süslü parantez ‘ }’ ile biterler. { ve } parantezleri arasındaki tüm ifadeler, ifade bloğunun gövdesini oluşturur. Örneğimizde; yerde 4 cm kar var ise montumuzu giyeriz, kar küreğini alırız ve yerdeki karları kenara atarız. Eğer yerdeki kar 4 cm’den az ise bu sefer de farklı bir ifade bloğu işleme tabi tutulur ve yatağa geri döneriz. Bu kadar basit.
Fonksiyon blokları
Fonksiyon blokları tek bir görevi yerine getirmek için dizayn edilmiş kod bloklarıdır. Aslında az önce farkında olmasak da bir fonksiyon bloğu kullandık. KardaCalismaKiyafetleriniGiy(); montunuzu giymenizi sağlamak için tasarlanmış olan bir fonksiyondu. Kod gerçekte şu şekilde görülebilir:
void KardaCalismaKiyafetleriniGiy(void) {
if (Kiyafetin Yoksa) {
KİyafetleriniGiy();
ÇoraplarınıGiy();
}
DolabaGit();
BotlariniGiy();
EldivenleriniGiy();
BereniGiy();
}
Örnekte de görülebileceği gibi, fonksiyon blokları da { ile başlar ve } ile biter. Fonksiyon blokları genellikle birşeylerin nasıl yapıldığının tarif edildiği ve bu tariflerin içine gömüldüğü kara kutular oluşturmak için yazılır.
Mesela, sensörlerle önündeki nesneleri algılayan bir robotu kontrol eden bir kod yazdığınzıı düşünebilirsiniz, SagaDon() fonksiyonu ile robotunuzu 90 derece saga döndüren bir fonksiyon yadığınızı düşünebilirsiniz. Bunu muhtemelen bir tekerleği durdurup diğer tekerleği çalışmaya devam ettirerek veya ön sağ tekerlekteki step motora daha fazla voltaj vererek yapabilrsiniz, yöntemi siz belirleyeceksizniz. Detaylarını sizin bileceğiniz şekilde motoru sağa döndürecek fonksiyonu SagaDon() kara kutusu içerisinde nasıl yapılacağına siz karar veriyorsunuz. 3-5 sene sonra robotunuzu modifiye edip değiştiridiğinizde SagaDon() fonksiyonu içindeki gerekli değişiklikleri yaparak robotunuzu yeni haliyle saga döndürebilirsiniz. SagaDon() fonksiyonunu yazarak, program içinde her sağa dönüş gerektiği anda ayrı ayrı sağa dönme kodları yazmak yerine , gerektiğinde sadece yazdığınızSagaDon() fonksiyonunu çağırmak yeterli olacak. Fonksiyon blokları bu iş için dizayn edilmiştir, yapılacak olan işi blok içinde tarif edersiniz ve gerektiğinde ilgili yerde fonksiyon bloğunu çağırarak işi yaptırırsınız.
Bir program yazmamız gerektiğinde, bütün işi tamamlayıp baştan sona çalışır hale getirmenin milyonlarca farklı yöntemi olabilir. Programı yazan her farklı kişi eminim kendi farklı yolundan gidecektir. Peki bir programı yazmaya nereden başlayacağız?
Beş Program Adımı
Düşünebileceğiniz her program, 5 temel program elementi yada adımına indirgenebilir. İlk dizayn etmeye başlayacağınız zaman bir programı aşağıda belirtilen 5 program adımı kavramında düşünebilirsiniz.
1- Başlangıç Adımı
Başlangıç adımının amacı, programın çalışacağı ortamı hazırlamaktır. Örneğin eğer exel,word yada benzer programlar kullandıysanız Dosya sekmesi altındaki menülerde en sık kullanılan dosyaların listesi bulunmaktadır. İnternet browserınız sizin, ana sayfayı ayarlamanıza izin verir. Bir çizim programının default bir printeri tanımlıdır. Bir veritabanı programı sıklıkla bir default internet bağlantısı sağlar. Belirttiğimiz tüm bu durumlarda, veriler bir yerlerden alınır ( veri dosyası, memory, EEPROM veya kayıtçılar) ve programın çalışacağı bir ana çizgi ortamı oluşturmak için kullanılır.
Basitçe söylemek gerekirse başlangıç adımı, programımızın öncelikli görevini yerine getirmeye başlayabilmesi için arka planda ne hazırlık yapılması gerekiyorsa hepsini hazır ve tamam hale getirir.
2- Giriş Adımı
Aşağı yukarı tüm bilgisayar programları; bilginin o andaki mevcut halini alıp, bir işleme tabi tutup ve bilginin yeni halini ortaya koymak için dizayn edilmiş bir görevleri vardır. bir yangın alarm sistemi yazıyorsanız yanıgn sensörlerinin sağladığı verileri alırsınız, mevcut durumlarını tercüme edersiniz ve eğer yangın var ise bunun için birşeyler yapmasını sağlarsınız. Eğer sensörler herhangi bir yangın göstermiyorsa, belki de 2. bir sensör seti okuması yapılır ve bu işlem sürekli olarak tekrarlanır. buna rağmen, belkide programınız günlerce hiçbir bir şey yapmayacak ancak her birkaç saniyede bir sensörleri yeniden okuyarak mevcut durum bilgisini programa ileterek işleme tabi tutacak ve bir müdahaleye gerek olup olmadığını değerlendirecek. Günü geldiğinde, yangını algılayacak ve gerekli müdahalenin yapılması için gerekli aksiyonu ortaya koyacak. işte bu haliyle tüm uygulamanın çalışması, düzenli aralıklarla yeni ve taze bilgilerin sensörlerden okunması ve sisteme girilmesi ile mümkün.
Giriş adımı, eldeki görevin çözümlenmesinde ihtiyaç duyulan gerekli bilgilerin tedarik edilmesi için hazırlanmış olan program ifadeleri silsilesidir.
3-İşletme Adımı
Yangın alarm sistemi örneğinden devam edecek olursak. Sensör girişlerinden okunan bilgiler her seferinde, yangın olup olmadığı ile ilgili değerlendirmenin yapılması için kodun bir bölümünün sorumluluğunda işleme tabi tutulacaktır. Kodumuzun o bölümü yangın olup olmadığı ile ilgili kararı vermekten sorumlu olmalıdır. Diğer bir deyişle, Girişlerdeki voltajlar okunmalı (örneğimizdeki duruma göre sıcaklığa göre voltaj seviyesi) ve bu bilgiler tercüme edilerek (işletilerek) sensörlerin mevcut durumu hakkında karar verilmelidir.
Bir masaüstü bilgisayarı uygulamasında, veri girişleri belki de ürünün fiyatı ve stışı yapılacak olan ürünün adedi olabilir, buradaki İşletim adımı da müşterinin toplam masrafının ne kadar olduğuna karar veren görevi işletmek olurdu.
Bir programda birden fazla işletme adımının olabileceğini not edelim. Tüm durumlarda İşletme Adımı, bir giriş bilgilerini bir set olarak almak ve bu giriş bilgi setini işleterek yeni bir bilgi seti elde etmekten sorumludur.
4- Çıkış Adımı
İşletme adımı görevini tamamladıktan sonra, elde edilen yeni değerler genellikle bir görüntüleme cihazı üzerinde çıkarılarak gösterilir. Müşteri satışı örneğindeki, müştrimizin toplam borcunu görüntüleme cihazında gösterebiliriz. Elbette Çıkış adımı sadece çıkışları bir görüntüleme cihazında göstermekle sınırlı olamaz. Sıklıkla, çıkış adımındaki yeni veriler bir yere kaydedilir veya başka programlara gönderilir. Yangın alarmı örneğimizde ise çıkış adımı, normal koşullar altında çalışan her bir sensör için yeşil ışık veren bir led olabilir. Eğer yangın algılanırsa, o sensöre ait olan led kırmızı yanar ve görevli kişiye kırmızı ledin göründüğü bölgede yangın olduğunu bildirebilir.
Çıkış adımı, İşletme adımının ürettiği sonuçların kullanılmasından sorumludur. Bu kaynakların kullanımı, verilerin bir görüntüleme cihazında gösterilmesi olduğu gibi verilerin başka programlara gönderilmesi de olabilir.
5- Sonlandırma Adımı
Sonlandırma adımı, program görevini bitirdikten sonra ortalığı temizlemekten sorumludur. Genel olarak başlangıç adımının terse doğru işletilmesi olarak da düşünülebilir. Eğer başlangıç adımında bir veri tabanı açıldıysa yada bir printer bağlantısı sağlandıysa, sonlandırma adımında bu bağlantılar kapatılır ve sistem için kullanılabilir kanaklar tekrar oluşturulur.
Birçok mikroişlemci uygulaması, her nasılısa, sonladırma için dizayn edilmemiştir. Bir alarm sistemi herşey normal olduğu sürece sonsuza kadar çalışmasını sürdürmek için tasarlanmıştır. Böyle bir durumda bile sonlandırma adımı tasarlanabilir aslında. Örneğin eğer yangın sistemindeki komponenetlerden bir tanesi bozulursa, sonlandırma adımı sistemi bakıma alınması için kapatmadan önce arızanın nerede meydana geldiğini tespit edebilecek şekilde tasarlanabilir. Yada bakım duruşundan önce sistemi alarm deaktive edebilir.
basitçe söylemek gerkirse, sonlandırma adımı mevcut çalışan programı düzgün ve kontrollü bir şekilde sonlandırılması için kullanılır.
Beş Program Adımının Amacı
Kendimize şu soruyu sorduğumuz olmuştur: ” nerden başlayacağım?”
Beş program adımı, dizayn edilecek program için bir başlangıç noktasını belirlemeye hizmet eder. Programın yapacağı iş tarif edildikten sonra hemen aynı dakika içinde kod yazmaya başlamak büyük bir hatadır. Verilen programın her bir adımı için 2-3 cümlelik ifadelerle işi tanımlamak, başlangıç noktası için yeterli olacaktır. Algoritma, istenilen sonuçları elde etmek için verilen giriş bilgi setlerinin nasıl idare-sevk edileceğinin resmi ifadelerle belirtilmesinden başka birşey değildir. Algoritma bir yemek tarifi yada detaylı bir plan gibidir, istenilen sonuca veya varış noktasına ulaşmak için ihtiyaç olunan şeyleri detaylıca açıklar. Bu yüzden programlamada, beş program adımı bir plan çerçevesinde formüle edilerek verilen programlama problemi çözümlenebilir.
hernekadar algoritmalar daha çok 2. ve 3. adımlar (giriş ve işletme adımları) ile daha sıkı ilişkilendirilse de, beş program adımı eldeki görevi çözümlemek için bir algoritma formüle etmekte yardımcı olabilir.
Blink programına bir ziyaret
blogdaki uygulamalar kısmında bu programı karta yükleyip nasıl çalıştığı anlatılmıştı. Bu programın nasıl çalıştığına, beş program adımı çerçevesinde bir göz atalım. Öncelikle aşağıdaki program, blink programının kaynak kodudur. Kaynak kodu ifadesi, programı oluşturan C kodu ifadeleri serisini gösterir. Kaynak kodu, C compiler tarafından parse edilir ( sözdizimi ve anlam olarak hata olup olmadığının kontrol edilmesi) ve en sonunda da mikroişlemcinin anlayacağı binary koda çevrilir (1’ler ve 0’lar). Neredeyse tüm kaynak kodları C dili ifadeleri ile oluşturulmuştur ancak hepsi değil.
/*
Blink
LED’i yakar 1 saniye bekler LED’i söndürü, bunu sürekli tekrarlar
*/
//Birçok arduinoda pin 13 e bağlı bir led kart üerinde bulunur. //13 nolu pine bir isim verelim:
int led=13;
// setup fonksiyonu reset butonmuna basınca yada karta enerji verince 1 kez çalışır
void setup() {
// dijital pini çıkış olarak ayarla.
pinMode(led, OUTPUT);
}
// loop fonksiyonu sürekli olarak tekrar tekrar çalışır
void loop() {
digitalWrite(13, HIGH); //LED’i yak (HIGH voltaj seviyesini gösterir)
delay(1000); // 1 saniye bekle
digitalWrite(13, LOW); // voltaj seviyesini LOW yaparak LED’i söndür
delay(1000); // 1 saniye bekle
}
Program Açıklamaları
programdaki ilk birkaç satır aşağıdaki gibiydi;
/*
Blink
LED’i yakar 1 saniye bekler LED’i söndürür, bunu sürekli tekrarlar
*/
//Birçok arduinoda pin 13 e bağlı bir led kart üerinde bulunur. //13 nolu pine bir isim verelim:
Dikkatli baktığımızda, yukarıda yazılı olan ifadelerin hiç birisi ; işareti ile bitmiyor bu yüzden bunların hiçbirisi C dili ifadesi formunda değildir. O zaman bunlar nedir?
Yukarıdaki satırlar yorum satırları olarak adlandırılır. Yorum satırları, programda neler yapıldığını programı daha sonradan okuyan kişiye anlatmak ve program ile ilgili dökümantasyonu yapmak için kullanılır.
İki temel tip yorum şekli vardır;
1- tek satır yorum ifadesi
2-çok satırlı yorum ifadesi.
Yorumum satırları hafızada yer kaplamazlar.
Tek Satır Yorum İfadeleri
bir çift slahs işareti ile başlar (//). bu işaretler arasında boşluk olmamalıdır. Compiler bu 2 ifadeyi görür görmez, işaretlerin bulunduğu satırda işaretlerden itibaren satır sonuna kadar olan kısımda yazılanlar birer yorumdan ibaret olduğunu ve derlenmeye (compile) ihtiyacı olmadığını bilir. Yorum bu // ifadelerinden sonra satır sonunda mutlaka bitmelidir eğer yazılanlar bir aşağıdaki satıra sarkar ve önüne // işareti konulmazsa, compiler tarafından syntax (sözdizimi) hatası olarak algılanacaktır.
Bu tip yorum ifadelerine örnek olarak aşağıdakiler gösterilebilir;
//Birçok arduinoda pin 13 e bağlı bir led kart üerinde bulunur. //13 nolu pine bir isim verelim:
Çok Satırlı Yorum İfadeleri
bu ifadeler /* işaretleri ile başlar, yorum yazlır. kaç satır olduğu önemli deildir. yazılacak her şey bittikten sonra */ işareti konularak yorum kapatılır.
/* işaretleri arasında boşluk yoktur, aynı şekilde */ işaretleri arasında da boşluk yoktur.
Bu yorum ifade biçimi, uzun yarumlar için daha uygundur.
Bu yorum yazma şekline örnek olarak aşağıdaki satırlar gösterilebilir;
/*
Blink
LED’i yakar 1 saniye bekler LED’i söndürür, bunu sürekli tekrarlar
*/
Veri Tanımlamaları (data definition)
Programdaki bir sonraki satırda int led=13; ifadesini görüyoruz. İfadenin, led isimli bir integer (tamsayı) değişkeni tanımladığını görüyoruz. Atama operatörü (=) ile de bu değişkenin içine 13 değerinin atandığını görüyoruz. Veri tanımlamaları bu şekilde yapılıyor nacak bu ifadedeki son derece önemli detayları sonraki bölümlerde, değişkenler ile ilgili konuları anlatırken ayrıntılarıyla açıklayacağız.
setup() Fonksiyonu
// setup fonksiyonu reset butonuna basınca yada karta enerji verince 1 kez çalışır
void setup() {
// dijital pini çıkış olarak ayarla.
pinMode(led, OUTPUT);
}
En üstte setup fonksiyonunun ne işe yaradığını anlatan bir yorum ifadesi bulunuyor. Yazdığınız her programın içinde bir adet setup() fonksiyonu mutlaka olmalıdır.
setup(), tüm arduino C programlarının çalışmaya başladığındaki başlangıç noktasını gösterir.
Standart C main() fonksiyonundan başlarken, arduino C ise setup() fonksiyonundan itibaren çalışmaya başlar.
setup() fonksiyonun arduino C nin başlangıç noktası olması nedeniyle, aynı zamanda da beş program adımın başlangıç adı olarak da görülebilir.
setup() fonksiyonu, programın çalışacağı ortamın tesis edilmesinden sorumludur.
Bu durumda başlangıç adımı, kart üzerindeki dijital I/O pinlerinden 13 nolu pini ÇIKIŞ (OUTPUT) olarak ayarlar. PinMode () isimli önceden yazılmış bir fonksiyon çağırılarak ve fonksiyonun işini yapması için gereken bilgiyi, argüman olarak ileterek bu yapıyı tesis eder. Yani, pinMode (), işini gerçekleştirmesi için “kara kutu” dünyasının dışında bulunan iki şeyi açıkça bilmelidir:
(1) programcı hangi pini ayarlamak ister ve (2) programcı, pinin bir giriş pini mi veya çıkış pini mi olarak çalışmasını ister? PinMode () için ilk argüman ayarlanacak olan pindir. Bu programda, programcı led pinini (yani, pin 13) ayarlamak istiyor. PinMode ()’un ikinci argümanı pin modunu belirtir. Bu programda, programcı pinin bir çıkış pini olarak çalışmasını ister. Diğer bir deyişle, pin üzerinden dış dünyadan girdi değerleri almak yerine diğer şeyleri kontrol etmek için pinin çıktısını kullanmak istiyoruz.
NOT: Genellikle “fonksiyon çağırma” ve “fonksiyona dönme” ya da “çağırana dönme” ifadesini okuyacaksınız. Bunlar, programcılar tarafından kullanılan ve aynı anlama gelen deyimlerin farklı birer yorumu olan yaygın olarak kullanılan ifadelerdir. Bir fonksiyonu ön ve arka kapıları olan bir kara kutu olarak düşünün. Kendinizi, program boyunca yürüyen, her bir program ifadesinin de yürütülmesine neden olan kişi olarak düşünün. “Bir fonksiyon çağırma” terimi dediğimi,zde şunu anlıyoruz. Herhangi bir zamanda bir “fonksiyon çağrıldığında” ; bir sırt çantası giydiğiniz, bu işlevin isteyebileceği herhangi bir bilgiyle doldurduğunuz ve daha sonra “fonksiyon çağırmak” için fonksiyona doğru yola çıktığınız anlamına gelir. Kara kutunun kapısı açılıyor ve içeri girip kara kutuda bulunan talimatları yerine getirmeye başlıyorsunuz. Kara kutunun dış dünyadan bilgi alması gerekiyorsa, görevini yapmaya başlamadan önce bu bilgi sırt çantanızdan alınır. Kara kutu bir işi yapar ve görevi tamamlandıktan sonra, sırt çantanıza bazı yeni şeyler koyabilir (veya olmayabilir). Ardından arka kapıya sizi yönlendirir ve sizi ilk etapta kara kutuyu ziyaret etmenize neden olan program noktasını izleyen noktaya geri gönderir. Bu hassas program noktasına geri dönme işlemi, “arayan kişiye geri dönme” veya “fonksiyondan geri dönme” olarak adlandırılır. Bu nedenle, “bir fonksiyonu çağırmak”, belirli bir görevi yerine getirmek üzere tasarlanmış önceden hazırlanmış program ifadelerine yönelik bir yolculuktan başka bir şey değildir. Bu görev tamamlandıktan sonra, program kontrolü, fonksiyon çağrısından hemen sonraki deyime geri döner.
Peki OUTPUT adındaki ikinci argüman nedir ve programda nerede tanımlanır? OUTPUT, sembolik bir sabittir ve derleyici içinde gömülü olan bir değişken adı olarak düşünülebilir. Sembolik sabit belirli bir veri değerine bağlı olan isimlerdir. Sembolik sabitlerin büyük harflerle yazılmış bir programlama usulü vardır. C dili, büyük / küçük harf duyarlı olduğundan output adlı bir değişkeni tanımladığınızda derleyici, sizin yazdığınız output isimli değişken ile OUTPUT adlı kendi simgesel sabitinin birbirinden farklı değişkenler olduğunu bilir.
Neden sembolik sabitler kullanılıyor? Basitçe ifade edildiğinde, program kodunun okunması daha kolay hale gelir. Bir programı hangisi gibi okumak istersiniz:
pinMode(led, OUTPUT);
veya
pinMode(led, 1);
kesinlikle ilk sıradaki kod daha açıklayıcıdır. OUTPUT ifadesi fonksiyonun ne yapacağını anlatmaya yetiyor.
Sembolik sabitler kullanmanın başka sebepleri de var ve bunları daha sonraki bölümlerde açıklayacağız. Şimdilik (basitçe) sembolik sabitleri, önceden tanımlanmış bir değere bağlı olan bir dizi büyük harf olarak düşünün.
Programın ilk çalıştırılmaya başladığında setup () fonksiyonunun yalnızca bir kez çağrıldığını hatırlamanız önemlidir. Bu nedenle, programımızdaki Başlatma Adımı olarak setup () öğesine başvurabiliriz. setup() ‘ı ikinci kez çağırmak istiyorsanız, arduino kartındaki resetleme düğmesine basmanız gerekir. Resetleme düğmesi, programın geçerli yürütmesini durdurur ve setup () fonksiyonunu çağırarak yeniden başlatır. PC’nizden, arduinoya program kodunun yeni bir sürümünü her yüklediğinizde, setup() fonksiyonu otomatik olarak (çoğu yeni Arduino kartı üzerinde) çağrılır.
loop() Fonksiyonu
Setup () fonksiyonu işini tamamladıktan sonra her Arduino C programı otomatik olarak loop () fonksiyonunu çağırır. Başka bir ifade ile, Setup () fonksiyon çağrısı ile Başlatma Adımı (Adım 1) tamamlandığından, Adım 2, Giriş Adımı için hazırız. Loop () fonksiyonu için kod şu şekilde türetilir:
// loop fonksiyonu tekrar tekrar sonsuz kere çalışır:
void loop() {
digitalWrite(led, HIGH); // LED’i yak (HIGH voltaj seviyesidir)
delay(1000); // 1 sn. bekle
digitalWrite(led, LOW); // voltaj seviyesini LOW yaparak LE’i söndür
delay(1000); // 1 sn. bekle
}
Döngü () fonksiyonu içinde program, digitalWrite () fonksiyonuna iki argüman gönderir ve digitalWrite (led, HIGH) adlı önceden yazılmış bir fonksiyon çağırır: (1) yazacağınız G / Ç pin numarası (örn. değişken led) ve (2) G / Ç pinini yerleştirmek istediğimiz durum (bu durumda HIGH). Yine, HIGH, derleyicide tutulan sembolik bir sabittir ve pini ON konuma getirmek istediğimiz anlamına gelir; bu sayede led’in bağlı bulunduğu G / Ç pinine voltaj sağlanır. Bu voltaj daha sonra LED’i yakar (ON konuma getirir).
DigitalWrite () fonksiyonunun amaçlarını not edin. İlk olarak fonksiyona şunu söyler: (1) hangi G / Ç pinde değişiklik yapılacağını ve (2) G / Ç pinini hangi konuma yerleştireceğini. Fonksiyon, bu iki bilgiyi aldığında (sırt çantası üzerinden!), LED istenen hali alır. Bu durumda, fonksiyon LED’i açar. Diğer bir deyişle, iki bilgiyi digitalWrite () ‘ya geçirmek Beş Program Adımımızın Giriş Adımı (Adım 2) olarak görev yapmaktadır. digitalWrite (), Giriş Adımından gelen verileri alır ve yeni aldığı girdilere göre LED’in durumunu değiştirdiği için, İşleme Adımının (3. Adım) bir parçası olarak da görev yapar. Bu girdiler göz önüne alındığında, LED bu noktada devreye girer. Yani, LED “ışıklar” ı görüntüler.
delay(1000) fonksiyon çağrısı, programın yürütülmesinde 1000 milisaniye (veya 1 saniye) duraklamaya neden olur. LED açık olduğundan, bu, aydınlatmayla LED’i izlememize izin verir. Eğer gecikme () fonksiyonu çağrısı programda kullanılmasaydı, LED o kadar kısa bir süre açık kalırdı ki gözümüz ED’in yandığını bile söyleyemezdi. Bu nedenle, operasyonel anlamda, delay () fonksiyon çağrısı, LED’in mevcut durumunu gözlemlememize izin vererek Beş Program Adımlarının Ekran Aşamasının (4. Adım) bir uzantısı olarak görev yapar.
Muhtemelen tahmin ettiğiniz gibi, sonraki dijital Write fonksiyonu (LED, LOW) çağrısı ve sonraki delay(1000) fonksiyonu LED’i 1 saniye süreyle kapatır. Bu yine de Süreç ve Ekran adımlarının bir parçasıdır. LED’i kapatmak, ekranın açılması kadar görüntüleme işleminin bir parçasıdır.
delay(1000) fonksiyonu bittiğinde, loop() fonksiyonunun kapanış parantezi okunur. Bununla birlikte, loop() bir program döngüsü olarak tanımladığından, program yürütümü döngüdeki ilk deyime geri döner ve dijitalWrite’dan başlayarak, döngüden ikinci bir geçiş gerçekleştirir (led, YÜKSEK). Bu, LED’i tekrar açar. Devrenin gücü kesilinceye dek bu sıra tekrarlanır; bu basitçe, LED’in orada olduğu sürece ve mc kartından güç çıkarılıncaya veya bir bileşen arızalanana kadar yanıp söneceği anlamına gelir.
Program sonsuza kadar döngüsel olarak çalışması için tasarlandığından, gerçekten Sona Erme Adımı yoktur (Adım 5). Çoğu mikrodenetleyici programı, bazı dış kuvvetler tarafından durduruluncaya kadar (örneğin, güç kaybedinceye kadar) yazılır. Bu genellemenin istisnaları vardır, ancak bunlar nispeten nadirdir.
Arduino C Veri Tipleri
Arduino C, ANSI C’nin veri türlerinin çoğunu birkaç önemli istisna dışında destekler. Ayrıca, floating point sayılarıyla devam eden küçük sürprizler de var, ancak “kaputun altında” neler olup bittiğinin farkında olduğunuz sürece sorun olmamalı.
Bölüm 2’de belirtildiği gibi, bir değişken, isim verilen bir yığın bellekten biraz daha önemli birşeydir. Bir değişkeni tanımladığınızda, derleyiciye bu değişkenle ilişkilendirilecek veri türünü de bildirmeniz gerekir. Değişkenin veri türü kaç tane bayt bellek verildiğini ve değişkende ne tür verilerin depolandığını belirlediğinden önemlidir. Bu bölümün sonraki bölümlerinde öğreneceğiniz gibi, iki temel veri türü vardır: değer türleri (value Types) ve başvuru türleri (reference Types). Değişken bir değer türü olarak tanımlanırsa, o zaman bu değişkene çok özel bir değer aralığı da vermek mümkündür.
Temel değer veri türlerinin bir listesi Tablo 3-1’de sunulmaktadır.
Table 3-1. Arduino C Value Data Types
Tür Bayt uzunluğu Değer aralığı
boolean 1 Mantıksal doğruya ve yanlışa sınırlı
char 1 Aralık: -128 – +127
unsigned char 1 Aralık: 0 – 255
bayt 1 Aralık: 0’dan 255’e
int 2 Aralık: -32,768 ila 32,767
unsigned int 2 Aralık: 0 – 65.535
word 2 Aralık: 0 – 65.535
long 4 Aralık: -2,147,483,648 ila 2,147,483,647
unsigned long 4 Aralık: 0 – 4,294,967,295
float 4 Aralığı: -3.4028235E + 38 ila 3.4028235E + 38
çift 4 Aralık: -3.4028235E + 38 ila 3.4028235E + 38
string ? Bir karakter dizisinden boş (‘\ 0’) sonlandırılmış başvuru türü veri yapısı
String ? Bir başvuru veri türü nesnesi
array ? Tek bir değişken adı tarafından başvurulan bir değer türü dizisi
void 0 Fonksiyon bir değer döndürmediğinde dönüş türü olarak fonksiyonlarla kullanılan bir tanımlayıcıdır.
C’de anahtar kelimeler
Tablo 3-1’de gösterilen her tür (diğer bir deyişle, boolean, char, int vb.), C’deki anahtar kelimelerdir. Anahtar kelime, C derleyicisi için özel anlam taşıyan herhangi bir kelimedir. Anahtar kelimeler derleyicinin kullanımı için ayrılmıştır, bu nedenle bunları kendi değişken veya işlev adlarınız için kullanamazsınız. Bunu yaparsanız, derleyici hata verecektir. Derleyici böyle hataları belirlemediysese, derleyici herhangi bir durumda hangi anahtar kelimeleri kullanacağı konusunda şaşkına dönecektir.
C’de Değişken İsimleri
Değişken veya işlev adları için anahtar kelimeleri kullanamazsanız, ne kullanabilirsin? C’de değişkenleri veya fonksiyonları adlandırmak için üç genel kural vardır. Geçerli değişken adları aşağıdakileri içerebilir:
1. a’dan z’ye ve A’dan Z’ye kadar olan karakterler
2. Alt çizgi karakteri (_)
3. İsminin ilk karakteri olarak kullanılmaması kaydıyla 0’dan 9’a kadar olan rakamlar.
C anahtar kelimeleri de dahil olmak üzere, her şey kabul edilebilir değildir. Bu da, noktalama işaretinin ve diğer özel olmayan yazdırma karakterlerine izin verilmemesi anlamına gelir. Geçerli değişken adları aşağıdakileri içerebilir:
jane Jane ohm ampere volt
money day1 Week50 _system XfXf
Aynı kuralları kullanarak, aşağıdakiler de geçersiz isimlerdir:
^carat 4July -negative @URL
%percent not-Good This&That what?
Bu sınırlar göz önüne alındığında, “iyi” bir değişken adı nasıl oluşturulur? Genel bir kural olarak, bir programda yaptıklarına dair bir ipucu verecek kadar uzun, ancak yazmaktan bıkmayacak kısa değişken adları iyidir. Birçok programcı tarafından kullanılan , camel notatin denilen şeyin bir blirtme türü vardır. Bu gösterimin kullanılışı şöyledir, değişken adları küçük harfle başlar, devamında glen her kelimenin ilk harfi büyük harf olarak devam eder. Bu stilin kullanılışına örnekler şunlar olabilir:
myFriend togglePrinter reloadEmptyPaperTray closeDriveDoor
Bu stil ile, değişken isimlerinin okumasının kolaylaştığını düşünüyorum. C hangi stili kullandığınızı daha az önemsiyor olabilir.
Ancak, her program yazarken mükemmel (hatasız) kod yazmanın mümkün olmadığını unutmayın. Anlam veren ve okunması basit değişken isimleri kullanmak, hata ayıklamayı çok daha kolay hale getirir. (C’nin büyük / küçük harfe duyarlı olduğunu unutmayın; bu, myData ve MyData’nın iki farklı değişken olduğu anlamına gelir.)
Bunu düşünerek, C programlarınızda kullanılabilecek ortak veri türlerini inceleyelim.
Boolean Veri Türü
Boolean veri türü iki değer veya durumla sınırlıdır: true veya false. Bu iki değer, derleyici içinde tanımlanmış sabitlerdir ve bir boolean değişkeninin alabileceği değerler yalnızca bu iki true veya false değerleridir. Bu nedenle, aşağıdaki satır bir boolean değişkeni için geçerli bir tanımdır:
boolean mySwitch = false;
muhtemelen bir anahtarın durumunu depolamak için kullanılacak bir değişken tanımlaması yapılmıştır (örneğin, anahtarın açık olduğu doğrudur).
Bununla birlikte, aşağıdaki parça gibi kod da görebilirsiniz:
boole switchState;
// bazı program deyimleri, açılama satırı
switchState = ReadSwitchState (whichSwitch);
if (switchState) {
TurnSwitchOff (whichSwitch);
} else {
TurnSwitchOn (whichSwitch);
}
Bir sonraki bölüme kadar if ifadesini ele almasak da, muhtemelen burada neler olup bittiğini anlayabilirsiniz. ReadSwitchState () fonksiyonu, anahtar açıksa boolean değeri olarak true değeri değeri döndürür veye anahtar kapalıysa boolean değeri olarak false değeri değeri döndürür ve bu durumlara göre değer alır. Boole veri türünü, yalnızca değişken doğru veya yanlış bir mantık durumunu yansıttığında kullanmalısınız. Derleyicinin, iki durum için atadığı gerçek değerleri bilmenize gerek yoktur.
Bununla birlikte, False durumunu sıfır olmak (yani, switchState = 0) ve True durumunu da sıfır olmayan olarak (yani, switchState != 0) olarak düşünebilirsiniz.
yani;
Flase =0 (sıfır)
True !=0 (sıfır değil)
Char Veri Türü
Char veri tipi, tek bir karakteri 8 bitlik bir büyüklükte saklamak için kullanılır. Bu, hem işaretli hem de işaretsiz char veri türünü içerir. Tüm Arduino C veri tiplerinde, eğer işaret biti (veri tipindeki en yüksek bit) 1 ise, o zaman değer negatiftir. İşaretsiz veri tiplerinde işaret biti yoktur. Sonuç olarak işaretsiz sayılar, işaretli bir sayının iki katı büyüklüğünde bir maksimum değere sahiptir. Aşağıdaki bölümde binary sayı sistemi daha ayrıntılı olarak açıklanmaktadır.
Binary (İkili) veri Türü
Dijital bilgisayarlar yalnızca iki durumu anladığından dolayı, açık (1) ve kapalı (0), binary (2’li tabanda) sayı sistemi kullanırlar. Ne yazık ki, bizler 10’lu taban ile matematik işlemleri öğretilen sayı sistemleri ile büyüdük, bu yüzden 2’li taban ilk başta biraz garip görünüyor. Ancak, 2’li taban sayı sistemini anlamak zor değil.
Tablo 3-2’ye bakın. Dijital bilgisayarları, ikili doğasıyla tutarlı olan sadece iki değeri alabilen küçük bir veri parçası olarak düşünebilirsiniz: (“açık” yani 1) veya (“kapalı” yani 0). Çoğu Merkezi İşlem Birimi (CPU) grubu, bitleri bir bayt olarak adlandırılan tek bir varlık haline getirir. Her bayt, 8 bitten oluşur. Çoğu programlama dili, bitleri saymaya başlarken 1’den ziyade 0 sayısı ile saymaya başlar. Bu nedenle, bir bayttaki bitler, bit 0 ile başlar ve bit 7 ile biter. 8 bitlik bir bayt için “yüksek” bit, bit 7’dir. “işaret biti” olarak da kullanılır. Örneğin, Eğer bir char veri türü için bit 7 “1” ise sayı negatif bir değer olarak yorumlanır. Eğer bit 7’nin tüm değerlerini “sağa doğru” toplama işlemi yaparanız (örn. , 64 ile 1 arası), o zaman toplamda değerin 127 olduğunu görürsünüz. Tablo 3-1’de bir char veri türü aralığına bakarsanız, en yüksek değerin 127 olduğunu görürsünüz. Eğer bir char veri tipinde bit 7=1 değerinde ise , bu negatif bir sayıdır, bu yüzden değer -128 olur. Bu, farklı veri türleri için aralıkların nasıl ayarlandığını anlamanıza yardımcı olur . İşaretsiz bir veri türü için (örneğin, unsigned char, unsigned int, unsigned long), işaret biti yoktur, bu yüzden yüksek bit sadece pozitif bir değerdir. Yine, bu işaretsiz bir sayı için maksimum değerin işaretl bir sayının neden iki katı olduğunu açıklar.
Şimdi, Tablo 3-2’yi daha ayrıntılı olarak inceleyelim.
Table 3-2. The Base 2 Interpretation of an 8 -Bit Data Value
Bit 7 Bit 6 Bit 5 Bit 4 Bit 3 Bit 2 Bit 1 Bit 0
2’nin katları 2^7 2^6 2^5 2^4 2^3 2^2 2^1 2^0
Decimal (10’luk) değeri 128 64 32 16 8 4 2 1
2’li sayı (örnek) 0 1 0 0 0 0 0 1
2’li sayının 10’lu değeri 64 1
Tablo 3-2’de, bit konumlarının 2’nin çeşitli güçlerine nasıl karşılık geldiğini görebilirsiniz. Örneğin, 2 değerini alıp 6. güçe yükseltirseniz, sonuç değeri 64’tür. Lise matematikinizi hatırlarsanız 0 gücüne yükseltilen herhangi bir sayı 1’dir. Bit 0’dan sola hareket ettirdiğinizde, değerlerin bir sonraki bit konumuna nasıl 2 katına geçtiğini görebilirsiniz.
Soru şu: Bir ikili değeri nasıl oluşturabilirim? Ondalık (taban 10) değerini 65 oluşturmak istediğinizi varsayalım. Bu değeri oluşturmak için 0 ve 6. bitleri “1” yapmanız gerekir. Çünkü 2’nin 0 ıncı gücü 1 ve 2’nin 6 ıncı gücü 64’tür.Bu iki değeri birbiri ile topladığınızda (64+1) 65 değerini üretir. Peki, 5 değerini nasıl yaratırsınız? 0 ve 2 bitlerini “1” yaparsanız, 5 değerini alırsınız (ör. 00000101). 10’a ne dersin? Bu durumda, bitleri 3. ve 1. bitleri “1” yapın (ör. 00001010).
Burada önemli bir detay var!
Tüm bitlerin bir konum sola kaydırılması, sayıyı 2 ile çarpmakla aynıdır. Aynı şekilde, tüm bitlerin bir konum sağa kaydırılması, 2’ye bölmek ile aynıdır. Arduino C, bit kaydırmayı destekler ve bazı kodlarda bunun örneklerini görebilirsiniz. Bunun hakkında daha sonra söyleyecek daha çok şeyimiz olacak. Bit kaydırma işlemi sadece int veri türleri ile yapılabilir.
Char Veri Türü ve Karakter Setleri
Bilgisayarlar ilk ortaya çıktığında, gerekli görülen tüm karakterler nispeten az değerle temsil edilebiliyordu. Örneğin, klavyenizin üzerinde 127’den az tuş vardır.
Gerekli olan nispeten az sayıda karakterden dolayı, Amerikan Standart Bilgi Değişimi Kodu (ASCII) karakter seti 8 bit (yani, 1 bayt) değerlerine dayanarak geliştirilmiştir. 8 biti işaretsiz bir büyüklük olarak ele alarak, ASCII karakter kümesi de sınırlı grafik karakterleri içerecek şekilde genişletildi. ASCII karakter seti onlarca yıldır normdu. Bununla birlikte, bilgisayarlar dünya çapında yayıldıkça, karakter kümesini genişletme ihtiyacı bariz hale geldi. Japon Kanji karakter kümesinin içinde yaklaşık 2.000 karakter var. Açıkça, bu karakterler 8 bitlik bir baytta temsil edilemez. Bu sebepten dolayı Unicode karakter kümesi geliştirildi. Unicode karakter kümesi, her karakter için 2 baytlık bir değere dayanır. Bir programcının bakış açısından, Unicode karakterleri işaretsiz büyüklüklerdir – dolayısıyla 65.000’den fazla karakter gösterilebilir. (Tablo 3-1’deki 2 baytlık değer aralığına bakın. Unicode karakter kümesinin ayrıntıları için bkz. http://www.unicode.org/charts. ASCII karakter kümesi için bkz. Http: //www.asciitable .com.) Bilgisayar yazılımını “uluslararasılaştırma” arzusu nedeniyle, daha fazla programcı, Unicode karakter kümesi kullanmaya başladı. Bununla birlikte, aynı zamanda, ASCII programcıları da vardı. Bunların hepsi için ortak kullanım imkanı tanıyan, farklı bit uzunlukları için Unicode karakter setleri vardır. Örneğin, UTF-8, 8 bitlik karakter kümeleri için Unicode Dönüştürme Biçimidir. Artık UTF-8, UTF-16 ve UTF-32 arasından seçim yapabilirsiniz.
Bu kitapta ASCII (1 byte) karakter setini kullanacağız. Yazılımınızda Unicode’a ihtiyacınız varsa, Arduino C’yi kullanarak bir programınız için gerekli olan uygunlaştırmayı yapabilirsiniz.
ASCII Karakterleri Tablosu Oluşturma
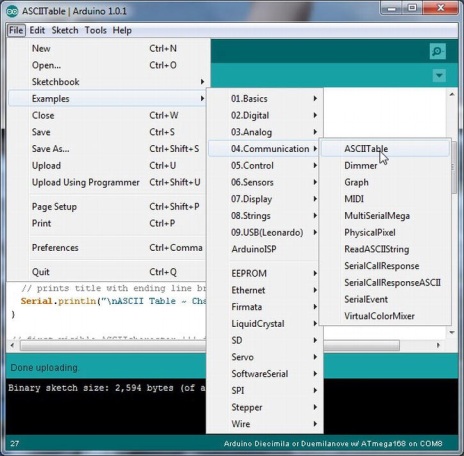
Arduino C IDE’nin içerdiği örnek programlardan biri, ASCII karakter kümesinin bir tablosunu oluşturabilen bir programdır. Şekil 3-1’de izlenecek menü sırasını görebilirsiniz.
Dosya – Örnekler – 04. İletişim – ASCIITable
menü dizisi programın kaynak kodunu yükler. Derleyin ve yükleyin
Bölüm 1’de yaptığınız gibi, Derleme ve Yükle düğmelerine (yani, Dosya menüsü seçeneğinin hemen altındaki Onay ve Ok tuşları) basarak programı başlatın. Şimdi Araçlar – Seri Monitör menü seçimini seçin veya aynı anda Control, Shift ve M tuşlarına aynı anda basın. Bu, Seri Monitörü açar, böylece veriler bilgisayarınıza geri gönderilir.
Bir kez daha, kodun üzerinden geçmeyeceğiz çünkü bunu anlamlandırabilmek için henüz kemerlerimiz altında yeterli yeteneğe sahip değiliz. (Bir sonraki bölümde ilk programınızı yazacaksınız.) Şimdilik, ASCIITable.ino programı en azından karakter, ondalık (taban 10), onaltılık (taban 16), sekizlik (taban 8) ve ikili (taban 2) sayılar olarak görüntülenen ASCII karakterlerini görmenize izin verecektir.
Şekil 3-2, ASCIITable programından çıktının bir kısmını sunar. Çıktıyı programdan inceleyerek, farklı numaralandırma sistemleri arasındaki ilişkiyi görebilirsiniz.
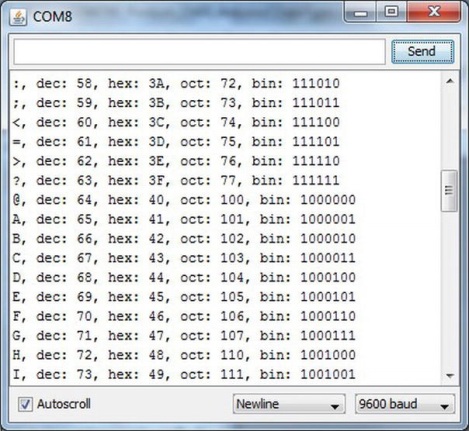
Şekil 3-2’deki en sol kenara yaklaşık olarak ortalara doğru bakarsanız, ‘A’ karakterini görürsünüz. Eğer bir değişken oluşturmak ve içine ‘A’ harfini yerleştirmek istiyorsanız o zaman aşağıdaki satırı kullanabilirsiniz. :
char c = ‘A’;
Derleyici bu ifadeyi işledikten sonra, c değişkeni “A” harfini içerir. Atama ifadesinde kullanılan karakter sabitlerinin tek tırnak işaretleri ile çevrildiğini unutmayın. “A” satırını okursanız, sayısal değerin (65) “A” harfini temsil ettiğini görebilirsiniz. Bu,
Shift tuşuna ve klavyenizdeki A harfine dokunduğunuzda, 65 değeri bilgisayarınıza aktarılır. Eğer 16’lık tabanda sayıyı düşünmeyi tercih ederseniz, 41 değeri gönderilir (yani, 16 * 4 + 1 = 65). 8’lik tabanda, değer 101’dir (yani, 8 * 8 + 0 + 1 = 65) veya ikilik sistem için Tablo 3-1’e bakınız. Ancak, bilgisayarlar sadece 0 ve 1’leri anladığından bilgisayar aslında klavyeden gelen “A” karakterini 01000001 ikili değeri olarak alır.
Bayt Veri Türü
Bayt veri türü de 8 bitlik bir değerdir, ancak işaret biti yoktur, bu yüzden aralığı bir karakterin neredeyse iki katıdır.
(İşaretsiz bir karakterin neden bir bayt ile aynı aralığa sahip olduğunu açıklayabilir misiniz? Bunu düşünün.) Herhangi bir değeri 0 ile 255 arasında saklamak için bayt veri türünü kullanabilirsiniz. Veri depolama için bellek alanınızı gereksiz yere tükettiğinizi düşündüğünüz durumda veya yeterli veri alanızın kalmadığı durumlarda veri tanımlamalarını, int veri türünden byte veri türüne değiştirmek, günü kurtarabilir. Yani aslında 8 bit veri saklayacağınız bir değişken için int tipinde veri tanımlamanıza gerek yok, bunun yerine byte veri tipini kullanabilirsiniz.
En yaygın kullanılan 8 bit veri türü char’dır. Ancak, ihtiyacınız olduğunda bayt kullanılabilir.
İnt Veri Türü
İnt veri tipi, C’de tamsayılar için kullanılan bir veri tipidir ve işaretli olarak da kullanılabilir. Bir int işaretli bir büyüklük olduğu için, int pozitif veya negatif tam sayıları saklayabilir. (Bkz. Tablo 3-1.)
Tamsayı veri türleri için ondalıklı değerlere izin verilmez. Tamsayı değerleri olan bir matematik işlemi ondalıklı bir değer (ör., 5/4) verirse, bu ondalıklı değer yoksayılır ve yalnızca tam sayı kısmı korunur (yani 5/4 işleminin sonucu 1,25 değil 1’dir).
Arduino C’de, bir int veri tipi Tablo 3-1’de gösterildiği gibi 16 bitlik bir değerdir. Diğer bazı dillerde (ör. Java, C #, C ++), int genellikle 32 bitlik (4 bayt) bir varlıktır. Bu diğer dillerin bazılarında önceden program yazdıysanız, Arduino C’deki bir int’nin diğer programlama dillerine taşıdığından daha küçük bir sayısal aralığa sahip olduğunu bilmeniz gerekir. (Genellikle, bir int veri türünün gerçek bit boyutu, ana bilgisayardaki kayıtların bit boyutudur.)
Ayrıca imzasız int veri türlerine sahip olabileceğiniz için, pozitif değerlerin üst sınırını neredeyse iki kat artırabilirsiniz. Ancak, bu büyük aralığın bedeli, işaretsiz veri türlerinin negatif değerleri saklayamamasıdır. İnt veri türü çoğu programda işaretsiz int veri türünden daha sık kullanılır.
Word Veri Türü
Tablo 3-1’de görüldüğü gibi, word veri tipi, işaretsiz bir int ile aynı depolama gereksinimlerine ve değer aralıklarına sahiptir. Bu durumda, işaretsiz bir int kullanıldığında bile neden bir word veri türü var? Terim sözcüğü aslında assembly programlama dili ile daha ilişkilidir ve CPU tarafından tek bir komutla işlenebilen en büyük bit grubunu yansıtır. Word veri türünü kullanmanın zor ve hızlı bir kuralı olmasa da sıklıkla, bit manipülasyonları veya onluk (taban 10) sayıların yerine onaltılık (taban 16) sayıların kullanıldığında bir değişken olarak tercih edildiğini görürsünüz.
Daha sonraki bölümlerde bit manipülasyonlarını inceleyeceğiz. Şimdilik, word veri tipini, işaretsiz (unsigned) int ‘e benzer olarak düşünebilir, ancak düşük seviyeli veri manipülasyonları önermek için kullanabilirsiniz.
Long Veri Türü
Long veri türü 32 bit (4 bayt) kullandığı için, artı veya eksi 2 milyar arasında bir değer aralığı vardır. Şimdiye kadar tartışılan diğer veri türleri gibi, Long veri tipi de bir tamsayı veri türüdür ve bu nedenle, kesirli değerleri temsil etmek için kullanılamaz. Ancak, 231 olası değer olduğu için (32. bit işaret bitidir), değerler aralığı çok büyüktür. Genel bir kural olarak, bir program için tüm olası veri değerlerinin int kapsamı içinde kaldığından ve yeterli olduğundan eminseniz, uzun veri tipi kullanmanızın bellek gereksinimlerinden başka bir sebep yok ise, int veri türü uzun veri türünden daha iyi bir seçimdir. Ayrıca, burada kullandığımız Atmel mikroişlemcinin tüm registerleri 8 bit (1 bayt) kayıtçıları kullanıyor. Bu nedenle, bir int için 2 bayt veri taşınması genellikle bir long için 4 bayt veri taşımaktan daha hızlı olacaktır. Kullanım yerine göre veri tipi seçimi yapmak program performansı açısından küçük de olsa bir fark yaratacağı göz önünde bulundurulmalıdır.
Float ve Double Veri Tipleri
Arduino C, programlarda ondalıklı sayıların kullanılmasına izin veriyor. Yani, programınızda kesirli değerler kullanan veri değerlerine sahip olabilirsiniz çünkü her bölme işleminin sonucu tamsayı olmayabilir.. Aslında, Arduino.h başlık dosyasına bakarsanız (genellikle arduino-1.0.1’de, donanım \ arduino \ cores \ arduino içerisinde bulunur), PI, TWO-PI ve benzeri için tanımlanan sembolik sabitleri bulacaksınız. Bu dosyada PI şöyle tanımlanır:
#define PI 3.1415926535897932384626433832795
bunun gibi siz de float bir sabiti şöyle tanımlayabilirsiniz:
float pi = PI;
ve derleyici PI için 3.1415926535897932384626433832795 numarasını tayin edecek ve bu değeri pi’ye atayacaktır. (C’nin büyük / küçük harfe duyarlı olduğunu unutmayın, bu nedenle pi ve PI, C’de farklı varlıklar olarak görülür) Bir float değişkeni için değerler aralığı yaklaşık olarak artı veya eksi 3,4’ün 38’inci gücü kadardır. Bu 38 haneye kadar olan büyük bir sayı değeridir. Her bir float 4 bayt depolama alanı gerektirir.
Çoğu dilde, double veri türü, float veri türünün gereksinimlerinin iki katına sahiptir (yani, 4 bayt yerine 8). Bu nedenle, değerler aralığı çok daha büyüktür (genellikle 308’inci güce bir değer). Bununla birlikte, Arduino C bir float ve bir double veri türleri arasında bir ayrım yapmaz. Her iki veri türü de Arduino C’de eşit olarak ele alınmaktadır.
Float veri tipinde virgülün Hassasiyeti
Bir sayının hassasiyeti, bu sayı için tahmin edebileceğiniz anlamlı basamakların sayısını ifade eder. Arduino C’de, float bir değer için beklediğiniz en yüksek hassasiyet, sayının ilk yedi basamağıdır. Bunun anlamı, 38 rakamlı bir float sayısını gösterebilmenize rağmen, sadece ilk yedi basamağı önemli. Kalan 31 hane, gözardı edilir. Bu gerçeği göz önünde bulundurarak, PI’nin olduğu gibi tanımlanması yanıltıcı görünmektedir. Tüm pratik amaçlar için, şöyle tanımlanabilir:
#define PI 3.141592
ve dijitlerin geri kalanını unutun çünkü bilgisayar bu rakamları herhangi bir matematik işleminde altı veya yedi basamaklıdan daha büyük bir hassasiyetle gösteremez. Bununla birlikte, eğer sadece pi gösterecek ve herhangi bir şekilde manipüle etmeyecekseniz, o zaman PI size önemli bir hassasiyetle sabit verir.
string Veri Türü
String veri türü, tek bir varlık olarak ele alınan ASCII karakterleri dizisidir. Başka bir deyişle, bir karakter dizisidir. String veri tipi birkaç farklı şekilde uygulanabilir. Ele alacağımız ilk konu, string’i bir karakter dizisi (array) olarak tanımlamaktır. Array, bir veri türünün bir veya daha fazla öğesinin gruplandırılmasından başka bir şey değildir ve bu öğelerin hepsinin ortak bir adı paylaşması gerekir. (Array’leri ilerleyen bölümlerde ayrıntılı olarak ele alacağız.) Bu durumda, bir string’i şöyle tanımlayabilirsiniz:
char myString [15];
İçinde 14 karakter barındırabilecek bir string için, hafızada yeterli alan ayırılır.
Neden 14 karakter ve 15 değil? Bunun nedeni, C’nin karakter dizisinin sonuna bir boş karakter (‘\ 0’) eklemesi gerektiğidir (null karakter). Derleyici, string’in sonunu işaretlemek için bu boş baytı kullanır. Bu nedenle herhangi bir string değişkeni, köşeli parantez içinde gösterilen sayının 1 eksiği kadar karakter saklayabilir. Örneğimizde, 15 karakter için yeterli belleği ayırdık. Bunlardan biri dize sonlandırma baytı tarafından kullanılması gerektiğinden (yani, boş karakter, ‘\ 0’), gerçek dize verileri için yalnızca 14 karakter kullanabiliriz. Arduino C, boş sonlandırma baytının ne zaman ekleneceğini bilecek kadar akıllıdır. Örneğin, aşağıdakilerin tümü, bir karakter dizisini (array) kullanarak bir string değişkenini tanımlamak ve başlatmak için geçerli yollardır.
char name [] = “Jane”;
char name [5] = “Jane”;
char name [100] = “Jane”;
İlk örnekte, derleyici, kaç baytlık depolama alanına ihtiyaç olduğunu anlar. Jane’in adı 4 karakterden oluştuğu için, isim ve boş sonlandırma karakteri için yeterli olduğundan emin olmak için 5 baytlık bir depolama alanı ayırır. İkinci formda, gerekli olan 5 bayt kod ile belirlenir. Son formda, 100 bir depolama alanı belirlenir; ilk dörtte “Jane” karakterleri bulunur ve beşinci karakter, dizeyi sonlandıran boş karakterdir (\ 0). Bu son biçim, gerekiyorsa programın başka bir noktasında 99 karakter uzunluğuna kadar genişleyebilmenizi sağlar. (Neden 99 karakter olduğunu biliyorsun.)
Dilerseniz karakter array (karakterleri tek tek belirterek) temelinde bir string de başlatabilirsiniz. Bu durumda, her karakteri tek tırnak işaretleri içrisinde belirtin, her karakteri bir sonraki karakterden virgülle ayırın. (Tek tırnak işareti tek bir karakter sabitini belirtmek için kullanılır. Çift tırnaklar, yukarıda görüldüğü gibi bir dizi karakter için kullanılır.) Örneğin:
char name[] = { ‘J’, ‘a’, ‘n’, ‘e’, ‘\0’};
char name[5] = { ‘J’, ‘a’, ‘n’, ‘e’, ‘\0’};
char name[] = { ‘J’, ‘a’, ‘n’, ‘e’};
char name[5] = { ‘J’, ‘a’, ‘n’, ‘e’};
Derleyicinin açık bir şekilde yazılmasa da boş sonlandırma karakterini bilmesi için yeterince akıllı olduğuna dikkat edin. Ayrıca, karakter bazında bir karakter dizisini (char array) başlattığınızda, başlatma listesinin bir süslü parantez ayracı başladığını da unutmayın ({ ) ve listeyi kapanış ayracıyla (}) sonlandırır. Listedeki karakterler, her biri diğerinden virgülle ayrılan tek tırnak işaretleri ile çevrelenir.
String Veri Türü
String veri türü, string veri türünden farklıdır (bu veri türünün büyük harf S ile başladığını not alın.) Bu veri türü, aslında string veri türünden oluşturulur, ancak basit bir karakter array yerine bir nesne olarak değerlendirilir. Bunun anlamı, String veri türüyle bir çok arduino yerleşik işlevini kolayca kullanırken, string veri tipiyle ise birçok şeyi kendiniz kodlamanız gerekir. Örneğin, bir sensörden, myData adlı bir string değişkenine okuduğunuz bir dizi karakter array’iniz olduğunu varsayalım. Dahası, hepsini büyük harflere dönüştürmeniz gerektiğini varsayalım. string veri türü ile, bu dönüşümü yapmak için kodu kendiniz yazmanız gerekir. Eğer myData’yı bir String nesnesi olarak tanımladıysanız, dönüşümü aşağıdaki gibi yazabilirsiniz:
myData = myData.ToUpperCase ();
Bunun nedeni, String nesnesi içinde sizin için dönüşümü yapacak kodu içeren özel bir fonksiyon (yöntem-method- olarak da bilinir) olmasıdır. Değişkeni sadece şöyle tanımlarsınız:
String myData = Dize (100);
myData adlı bir String‘i 99 karakter için yeterli alan ile tanımlar. Yerleşik bir fonksiyonu kullanmak için, değişken adını bir nokta ile (nokta operatörü olarak adlandırılır) ve ardından kullanmak istediğiniz fonksiyon özelliğini belirtin. Örneğin,
myData = myData.ToLowerCase ();
Bu işlevsellik, Nesne Yönelimli Programlama (OOP) paradigmasını destekleyen C ++, C # ve Java gibi programlama dillerinde yaygındır. Arduino C bir OOP dili olmasa da, dile eklenen bazı OOP özelliklerini görmek güzel. Tablo 3-3, String nesneleri kullandığınızda kullanılabilen yerleşik fonksiyonların bazılarını gösterir.
Tablo 3-3. Yerleşik String Fonksiyonları
Fonksiyon Açıklama
String() Bir String objesi tanımlar
charAt() İndex numarası belirtilen String karakterine erişimi sağlar
compareTo() 2 String’i birbirleri ile karşılaştırır.
concat() Bir String’i, diğer bir String in sonuna ekler
endsWith() String’in son karakterine bakar.
equals() 2 String’i karşılaştırır, eşit olup olmadıklarına bakar.
equalsIgnoreCase() 2 String’i karşılaştırır, büyük/çüçük harf duyarlı değildir.
getBytes() String karakterlerini, byte dizini içerisine kopyalar.
indexOf() Belirtilen karakterin index numarasını alır.
lastIndexOf() Başka bir String içindeki bir karakteri veya String’i bulur.
length() String içindeki karakter sayısını döndürür, null karakter hariç.
replace() String içindeki belirtilen karakterleri, verilen başka bir karakter ile değiştirmek için kullanılır. ( tüm a’ları b ile değiştir)
setCharAt() Belirtilen index’teki karakteri, verilen karakter ile değiştir.
startsWith() Bir String’in başka bir String karakterleriyle başlayıp başlamadığını test eder.
substring() Bir Dize içindeki alt dizeyi bulur.
toCharArray() String karakterlerini sağlanan char dizesine kopyalar.
toLowerCase() Tüm karakterleri küçük harfe dönüştürür.
toUpperCase() Tüm karakterleri büyük harfe dönüştürür.
trim() String’in önündeki ve arkasındaki boşlukları siler.
Şu anda bu işlevlerin tümünü kullanmaya hazır olmamakla birlikte, burada tümünü gösterebilmek için sunulmaktadırlar. Bazılarını sonraki bölümlerde kullanacağız.
Void Veri Türü
Void veri türü gerçekte bir veri türü değildir. Void anahtar sözcüğünün bir kullanımı, bir işlevin bir değer döndürmediğini göstermek için işlevlerle birlikte kullanılmasıdır. Örneğin, ASCII tablo programına bakarsanız, setup () ve loop () işlevleri şu şekilde tanımlanır:
void setup () {
// setup kodu gövdesi
}
void loop () {
// loop kodu gövdesi
}
Burada void’in kullanılması demek, bu iki işlevden de hiçbir veri döndürülmediği anlamına gelir.
Void’in bir başka kullanımı, işleve hiçbir bilgi iletilmediğini söylemektir. Başka bir deyişle, iki işlevi aşağıdaki gibi yazabilirsiniz:
void setup(void) {
// setup kodu gövdesi
}
void loop(void) {
// loop kodu gövdesi
}
Program tam olarak eskisi gibi derlenecek ve çalışacaktır. Arduino C kullanan çoğu programcı, bir işlevin açılış ve kapanış parantezleri arasında void anahtar sözcüğünü kullanmaz. Şahsen, bu bağlamda void’i kullanmayı seviyorum, çünkü kara kutuya dış dünyadan hiçbir bilgi aktarılmadığını doğrulamaya yardımcı oluyor.
Array (Dizin) Veri Tipi
Hemen hemen tüm temel veri türleri bu tür dizileri destekler. Şimdiden karakter dizisi örnekleri gördük. Aşağıdaki ifadeler diğer bazı dizi tanımlarını gösterir:
int myData [15];
long yourWorkDay [7];
float sıcaklık [200];
Bu ifadelerin her biri, belirli bir türden bir dizi (array) tanımlar. Bölüm 8’deki C işaretçileri (pointers) ile ilgili konuya kadar dizilerle ilgili ayrıntıları erteleyeceğiz. Bu bölümden önce herhangi bir özelliğe ihtiyaç duyarsak, ilgili detaylara gişrebiliriz.
Değişkenleri Tanımlamak (define) mı? Beyan etmek (declare) mi?
Çoğu programcı “tanım” ve “beyan” terimlerini sanki aynıymş gibi kullanırlar. Ancak, aynı değiller! Bu kitapta bir şey öğrenecekseniz bu, “bir değişkeni tanımlamak” ve “bir değişkeni bildirmek-beyan etmek” terimlerinin tamamen birbirinden farklı türler olacağıdır. Bu farkı göstermek için, val adında bir tamsayı değişkeninin basit bir tanımını alalım:
int val;
Bu masum bir ifade gibi görünse de, arka planda birçok işler oluyor. Neler olup bittiğini gözden geçirelim. Burada açıklanan temel esaslar, program derlemesi ve işlemesinde gerçekte olan şeydir. İlk olarak derleyici bu ifadeyi gördüğünde yaptığı ilk şey, sözdizimi hataları için ifadeyi kontrol etmektir. Bir tane bulursa, derleyici penceresinin altında görüntülenen şu çirkin turuncu hata mesajlarından birini alırsınız. Ancak yukarıdaki ifade doğru olduğundan derleyici, derleme işleminin bir sonraki aşamasına geçer (sembol tablolarına).
Sembol Tabloları
Bir sonraki adım, programda val tanımlanmış olup olmadığını belirlemek için derleyicinin sembol tablosunu taramasına neden olur. Tablo 3-4 basitleştirilmiş bir sembol tablosunu gösterir.
Tablo 3-4. Basitleştirilmiş bir Sembol Tablosu
ID Data type Scope lvalue …
myData int 0 20000
x float 0 20100
Tablo 3-4’te gösterildiği gibi, myData ve x değişkenleri zaten tanımlanmış iki değişkendir. ID (Kimlik) sütunu, Tanımlayıcı anlamına gelir ve tanımlanmış her değişkenin adı aynı zamanda ID’sidir. MyData öğesinin int veri türü olduğunu, oysa x’in float veri tipinde olduğunu görebilirsiniz. Her iki değişken de 0’lık bir kapsam seviyesine sahiptir (birkaç sayfa sonra buna değineceğiz). İlk üç sütunu bir değişken için bir nitelik listesi olarak düşünebilirsiniz. lvalue sütununu (location value), her bir değişkenin bellekte bulunduğu bellek adresini gösterir.
lvalue ve rvalue
lvalue, belirli bir veri öğesinin bellekte bulunduğu bellek adresini gösterir. Bu nedenle, bir veri öğesinin lvalue’si, o öğenin saklandığı hafıza alanı adresidir. lvalue’lerin anlamlı olması için derleyici, val’i tanımlamak için yazdığımız ifadenin sözdizimsel olarak doğru olduğunu belirledikten sonra ne olacağını düşünün. Derleyicinin yaptığı bir sonraki şey, val adında bir değişkeni daha önceden tanımlayıp tanımlamadığınızı kontrol etmek. Eğer daha önceden tannımlamış olsaydık, val için zaten sembol tablosunda giriş bilgileri olurdu. Öyle olsaydı, val için “yinelenen tanım hatası” alırdık. Bu noktada val için daha önceden tanımlanmış herhangi bir bilgi olmadığını varsayalım
Sembol tablosu şimdi Tablo 3-5’teki gibi olurdu.
Tablo 3-5. Val üzerinde Sözdizimi Kontrolü Sonrası Sembol Tablosu
ID Data type Scope lvalue …
myData int 0 20000
x float 0 20100
val int 0 ???
val için lvalue’nin hala bilinmediğine dikkat etmek önemlidir. Yani, val henüz hafızada yaşamak için özel bir yere sahip değil. Yine de, yinelenen tanım hatası olmadığından, derleyici işletim sistemine bir mesaj gönderir. (Bilgisayarınızın bazı Windows sürümlerini çalıştırdığını varsayıyoruz.) Temel olarak derleyici, Windows’a şöyle bir mesaj gönderir: “Hey, Windows! Benim, Arduino. Programcımın iki byte boş hafızaya ihtiyacı var. İsteğimi yerine getirebilir misin? ”Bu noktada, Windows iletiyi Windows Bellek Yöneticisi’ne verir; bu durumda kullanılabilir boş bellek listesini tarar ve bir yerde iki boş bayt bulur. Bulduğu boş hafızanın 20200 başlangıç hafıza adresinde olduğunu varsayacağız. Windows Hafıza Yöneticisi, Windows’a 20200 hafıza adresini içeren bir mesaj döndürür. Windows daha sonra Arduino’ya bir mesaj yollar: “Hey, Arduino! Benim, Windows. İki bayt boş belleği 20200 bellek adresinden başlayarak kullanabilirsiniz.” Bu noktada, derleyici Tablo 3-6 gibi görünmek üzere Tablo 3-4’ü değiştirir.
Tablo 3-6. Yeni val Değişkeni Eklendikten Sonra Sembol Tablosu
ID Data type Scope lvalue …
myData int 0 20000
x float 0 20100
val int 0 20200
Burada neler olduğunu not edin. Şimdi yeni val değişkeninin yaşadığı bir hafıza adresimiz var. Val değişkenini tanımladınız, çünkü bilinen bir hafıza adresine ya da değerine sahip. Bu nedenle:
• Bir veri öğesi, yalnızca sembol tablosunda bilinen bir değere sahipse tanımlanır.
• Bir veri öğesi sembol tablosunda mevcutsa, ancak atanmış bir değeri yoksa beyan edilir.
Kitapta daha sonra bir verinin bildirilmesi/beyan edilmesi örneği göreceksiniz. Veri tanımlamasının ise şu anlama geldiğini unutmayın; bir değişkeni , yine aynı değişkenin lvalue’sini kullanarak bulabiliriz. Veri beyanları, bir veri öğesi için özellik listesinden başka bir şey değildir. Yani bir veri öğesi için veri beyanları size, verinin kimliğini, türünü ve kapsam düzeyini söyler, ancak bellekte mevcut değildir. Veri beyanları çoğunlukla tip kontrolü amacıyla kullanılmaktadır.
lvalue’yi Şekil 3-3’te gösterildiği gibi basit bir şema ile gösterebiliriz. Şekil 3-3, Tablo 3-6’da görülen sembol tablosunun durumunu gösterir. val değişkeni artık tanımlanmıştır, çünkü bilinen bir lvaleu’si var ve bu nedenle de bellekte mevcut. (lvalue eski assembly dili programlama günlerinden gelir ve “location value’yi” temsil eder ya da bir veri öğesinin bellekte depolandığına dair bir referanstır. Bazı öğrenciler bunu “sol değer(left value)” olarak hatırlamayı daha kolay buluyorlar çünkü lvalue Şekil 3-3’ün “sol tarafını” oluşturuyor.
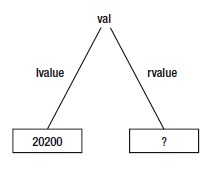
Şekil 3-3. lvalue-rvalue diagramı.
rvalue’nin bir soru işaretiyle işaretlendiğine dikkat edin. Bunun sebebi, rvalue’nin gerçekte lvalue hafızasının bulunduğu yerde neyin depolandığını göstermek için kullanılmasıdır. rvalue, veri öğesinin lvalue’sinde veya bellek konumunda depolanan şeydir. C statik olmayan bir veri öğesinin tanımlanması sırasında rvalue’sinin illaki sıfır olarak (yada başka bir değer) atanması gerekli olmadığından, bir veri öğesinin değerine açıkça bir değer ataması yapılana kadar lvalue değerinde rastgele bir bit kalıbı bulunduğunu varsayalım. Bu nedenle, val için rvalue’yi bir soru işareti olarak gösteriyoruz: lvalue’sinde ne kadar önemsiz bir değer olursa olsun. (rvalue de aynı zamanda assembly dili programlama günlerinden bir kalıntıdır ve “register value” anlamına gelir. Yine, bazı öğrenciler bunu “sağ değer(raight value)” olarak düşünürler, çünkü Şekil 3-3’teki “sağ bacağı” oluştururlar.
10 değerini val olarak atamak istediğinizi varsayalım. Bunu yapmak için ifade:
val = 10;
Yine, bu tek bir ifadeyi ve binary atama operatörünü içeren basit bir ifadedir. Ancak durun ve derleyicinin ifadeyi işlemesi için ne yapması gerektiğini düşünün.
1. İlk olarak, derleyici sözdizimi hataları için ifadeyi kontrol etmelidir. Orada sorun yok.
2. Ardından, derleyici val adında bir değişken olup olmadığını görmek için sembol tablosuna gitmelidir. Yine, her şey yolunda görünüyor çünkü val sembol tablosunda.
3. Daha sonra val geçerli bir lvalue (hafıza adresi) sahip olduğundan emin olur (yani hafıza adresi 20200). Eğer lvalue sütunu boşsa (sembol tablosundaki lvalue sütunundaki tüm satırlar, tablo oluşturulurken boş değer asla geçerli bir bellek adresi olmadığından boş bırakılır) derleyici bunun bir veri bildirimi/beyanı olduğunu ve değişkenin henüz tanımlanmış olmadığını bilir . Tanımlanmamış bir değişkenin kendisine atanmış bir değere sahip olamayacağı açık olmalıdır. Bununla birlikte, val geçerli bir hafıza adresine sahip olduğundan, derleyici atama deyimini işleyebilir.
4. Atama ifadesini işlemek için derleyici, veri öğesinin bellekteki lvalue’sine gider ve atama ifadesinin sağ tarafındaki değeri (ör., 10) lvalue adresindeki 2 bayt belleğe kopyalar. Bu işlem, rvalue’nin içeriğinin 10 olarak değiştirildiği anlamına gelir. Şekil 3-4’te gösterilmektedir. Eğer 20200 ve 20201 numaralı bellek konumlarına bakabiliyorsanız, şunu göreceksiniz: 00001010 00000000. (Çoğu PC ilk önce düşük baytı ve ikinci olarak da yüksek baytı depolar. Sonuç aynıdır: 10 değeri 20200 değerinde saklanır. )
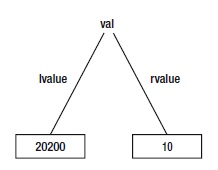
Şekil 3-4. Atama deyiminin işlenmesinden sonraki lvalue-rvalue diyagramı.
Programınızın val’de depolanan verileri kullanması gerektiğinde, val’in lvalue’sini bulmak, o hafıza adresine gitmek ve veriden “int bayt” (her int 2 bayttır) almak için bir sembol tablosu araması yapması gerektiğini unutmayın. (Burada anlama kolaylığı sağlaması açısından, bazı işlemler tanımlanırken kullandığım terimler için asıl işlem PC’nizde değil de mc board’unuzda gerçekleşti. Burada sunulan basitleştirme, değişkenlerin ve hafızanın bir programdaki ilişkisini anlamanıza yardımcı olması hedeflendi .)
Kova Benzetmesi
lvalue ve rvalue’nin anlaşılmasını ve ayrıntılarının hatırlanmasını kolaylaştırmak için geliştirdiğim Kova Analojisi gerçek bir C anlayışı için çok önemlidir. Diyelim ki etrafta bir sürü farklı büyük kova var. Her kova, belirli sayıda bayt veri tutacak kadar büyüktür. Bazı kovalar yalnızca 1 bayt veri tutabilirken, diğerleri 2 bayt tutabilir. Bazı diğerleri 4 byte tutabilir, vb. Daha önceden bahsettiğimiz Tablo 3-1’i kullanarak 1 baytlık bir kovanın; bayt, char, unsigned char veya boolean veri öğesi alabileceğini görebilirsiniz. Bir int, unsigned int veya word veri öğelerini saklamak için 2 baytlık bir kova kullanılabilir. 4 baytlık bir kova long, unsigned long, float veya double veri tipleri için saklama yeri olarak kullanılabilir. Bu farklı büyüklükteki kovalarla dolu bir odanız olduğunu varsayalım. Şimdi aşağıdaki program ifadelerini göz önünde bulundurun:
int val;
val = 10;
bu daha önce tartıştığımız ifadelerdi. İlk ifade, daha önce tartıştığımız gibi sembol tablosu bilgisini doldurur. Bununla birlikte Kova Analojisinde ilk ifade, kovanın boyutunu (2 baytlık bir kova) belirleyerek ve bu kovanın bellekte nereye yerleştirileceğinin belirlenmesi olarak düşünülebilir.
İkinci ifade, 20200 no’lu hafıza adresindeki val’in kovasına gittiğimiz ve 10 değerini oluşturacak şekilde düzenlenmiş verilerle kovaya 2 bayt veri döküldüğümüz anlamına gelir. Bu, Şekil 3-5’de görülebilir. Şekil ayrıca, eksi işareti karakteri için 20000 adresindeki bellek yerinde depolanan 1 baytlık bir kova da gösterir. 20000 nolu hafıza adresinde depolanan kova, val değişkeni içeriğini depolamak için kullanılan kovanın yarısı kadar büyüktür.
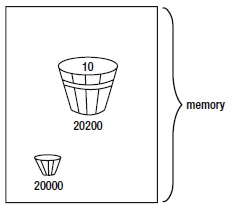
Şekil 3.5. val değişkeni tanımlanması için Kova Analojisi.
Kova Analojisi aşağıdaki üç sonucu verir:
• Bir kovanın büyüklüğü saklanan veri tipine bağlıdır.
• Kovanın bellekte saklandığı yer, veri öğesinin lvalue‘sidir.
• Kovanın içeriği veri öğesinin rvalue‘sidir.
Programlarınızda ne zaman bir değişken kullanıyorsanız, büyük olasılıkla lvalue’sini kullanarak ilgili adrese değişken veri tipine uygun bir kova yerleştiriyorsunuz ve o kovanın içeriğini (yani rvalue’sini), programınızdaki belirli ifadelerde kullanıyorsunuz.
Ayrıca, aşağıda bu kod parçasındaki son ifadenin dlvalue ve rvalue kullandığı açıkça anlaşılamlıdır:
int val = 10;
int toplam;
toplam = val;
Son ifadede, derleyici sembol tablosuna gider ve val değeriniin lvalue’sini bulur. Daha sonra val’in 2 baytlık kovasını almak için hafıza adresini (val’in lvalue’si) kullanır. Sonra toplam değişkeninin lvalue’sine bakar, bu hafıza adresine gider ve kovasını alıp getirir. Artık her iki işlenen de kullanılabilir durumda olduğundan atama işleci, derleyicinin val’in kova içeriğini toplam kovasına dökmesine neden olur. Bu nedenle bu işlem sayesinde, val’in kovasının içeriği, toplam kovasında bulunanların yerini alır.
Burada önemli bir ders var: Tüm basit atama ifadeleri, atama operatörünün sağ tarafındaki kovanın içeriğini, atama operatörünün sol tarafındaki işlenenin kovasına taşır. Ayrıca tüm basit atama ifadelerinde sağ işlenenin rvalue’sinin, sol işlenenin rvalue’sine taşındığı açık olmalıdır. lvalue ve rvalue hakkında düşünün ve C hakkında sağlam bir anlayış geliştirin.
